
I find what I learn in school very exciting and I want to share it with the world. I will be maintaining this series to recap on my favorite topics at the end of each semester.
Two of my favorite and most challenging classes this fall were Computer Architecture and Programming Language concepts and I'm excited to talk about some of the techniques I learned this semester.
Computer Architecture
In this class we started with how characters, integers, and floating point numbers are represented in binary. We refreshed ourselves on binary arithmetic and learned how the C language is interpreted into bytecode.
From there we moved onto how to decompile C programs into assembly using objdump and how to intepret the assembly language.
We used these skills in order to find when buffer and stack overflows occur, how to identify how gcc prevents overflows using a stack protector (canary) register. We also looked into program optimization when working with loops by interpretting how data structures are stored on the stack and how this affects iteration.
Binary Arithmetic
Adding binary numbers works in the same way as decimal numbers. For example 10101+10011 or 21+19
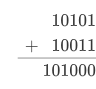
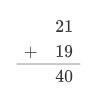
Subtraction works the same way as decimal subtraction, however, it requires a change of thought.
For example, with 124-8 you might cross of the 2 and carry 1 to the 8 to make 14-8. You are removing a value of 10, or ten 1's from the 20.
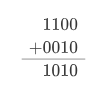
If you were to subtract 1100-0010 or 12-2. you would need to carry the 1 as well. However, when working in a power of two, you will not just be carrying the 1 you will be carrying two 1's which properly abstracts the full iteration of a digit in a 2's number system. This would result in 1010 or $10$.
Floating point numbers are the most interesting, they take up 32bits in single precision and can reach a surprising level of accuracy. This is done by encoding a number in scientific notation into the binary number system.
With only 32 bits, the number can only be so accurately represented. In cases where you cannot fit the number into 32bits, rounding occurs just like we do when reducing numbers in algebra.
Optimizing for Multiplication and Division
Multiplication and Division in binary can take several operations. Consider $a*b$, in order to multiply these numbers you would have to add $a$ b times. The more you multiply the more expensive it would be.
Thankfully, we can exploit a property of the binary numbering system, and reduce the required amount of operations using bitshift operators.
Lets keep this simple by using unsigned binary integers 4bits in length. Consider $42$, or $01000010$. We know the result would be eight, or 1000. Which traditionally would be:
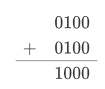
However, we could look at the multiplication as $x2^k$ where $k$ is the number factor of 2 for which you would like to multiply. Multiplying by 2 in a binary number system is the same as $2^1$ so we would want to bitshift <<1 in order to multiply by 2. 0100<<1 would become 1000 effectively multiplying by two in one operation.
If you wish to multiply by a factor that is not a multiple of two you would have to use multiple bitshift operations to reach the desired result.
For example $4*17$, we know this is $68$, on a computer this would take 17 addition operations. Using bitwise operations this can be made significantly faster:
0100 << 4 == 1000000 == 64 //4*(2^4)
1000000 + 0100 == 1000100 == 68
Here we performed the multiplication in only two operations! If you wanted to divide, you would use the inverse the same logic, by bitshifting to the right or subtracting. Bitshift operations make multiplication and division significantly faster.
Assembly in 1 minute
Assembly language is the closest we can get to working directly with a processor. The Intel assembly reference consists of hundreds of commands that can be used however many a very similar to the following basic commands:
mov a, b: moves data from register a into register bsub a, b: subtracts the value in a from the value in bcmp a, b: performs a comparison between a and badd a, b: adds value a to value blea -0x18(%a), %b: load effective address, computes the sum of-0x18andaand stores it inbje a: jump to address a if the last operation triggered the equal flag.
It is important to understand the cmp command and how it functions. When you compare two registers you actually perform a subtraction. You will subtract a from b and then an xor operation is run on the sign bit to determine if the result was negative or not. If the result is negative we know that a was greater than b and the appropriate condition code is triggered when the data exits the ALU.
Stack Overflows
Consider the following code inside so.c:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <limits.h>
int len(char *s) {
return strlen(s);
}
void lptoa(char *s, long *p) {
long val = *p;
sprintf(s,"%ld",val); // string print
}
long longlen(long x) {
long v;
char buf[8];
v = x;
lptoa(buf,&v);
return len(buf);
}
int main() {
longlen(INT_MAX-1);
}
If dump the assembly with objdump -d so.c > so-asm.txt. We can interpret the longlen function below:
0000000000401188 <longlen>:
401188: 55 push %rbp
401189: 48 89 e5 mov %rsp,%rbp
40118c: 48 83 ec 20 sub $0x20,%rsp # stack of 20bytes
401190: 48 89 7d e8 mov %rdi,-0x18(%rbp) #2 bytes for x
401194: 48 8b 45 e8 mov -0x18(%rbp),%rax #move stack ptr
401198: 48 89 45 f8 mov %rax,-0x8(%rbp) #8 bytes for buf[8]
40119c: 48 8d 55 f8 lea -0x8(%rbp),%rdx #move stack ptr
4011a0: 48 8d 45 f0 lea -0x10(%rbp),%rax # stack is filled
4011a4: 48 89 d6 mov %rdx,%rsi
4011a7: 48 89 c7 mov %rax,%rdi # 10 bytes copied to 2 byte space
4011aa: e8 a1 ff ff ff callq 401150 <lptoa>
4011af: 48 8d 45 f0 lea -0x10(%rbp),%rax
4011b3: 48 89 c7 mov %rax,%rdi
4011b6: e8 7b ff ff ff callq 401136 <len>
4011bb: 48 98 cltq
4011bd: c9 leaveq
4011be: c3 retq
The gcc compiler will detect the stack overflow and use a stack protector. If we recompile and dump the program again the same function will may look something like this:
0000000000401198 <longlen>:
401198: 55 push %rbp
401199: 48 89 e5 mov %rsp,%rbp
40119c: 48 83 ec 30 sub $0x30,%rsp #10 more bytes allocated
4011a0: 48 89 7d d8 mov %rdi,-0x28(%rbp)#2bytes for `v`
4011a4: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax #create canary
4011ab: 00 00
4011ad: 48 89 45 f8 mov %rax,-0x8(%rbp)
4011b1: 31 c0 xor %eax,%eax
4011b3: 48 8b 45 d8 mov -0x28(%rbp),%rax
4011b7: 48 89 45 e8 mov %rax,-0x18(%rbp)
4011bb: 48 8d 55 e8 lea -0x18(%rbp),%rdx
4011bf: 48 8d 45 f0 lea -0x10(%rbp),%rax
4011c3: 48 89 d6 mov %rdx,%rsi
4011c6: 48 89 c7 mov %rax,%rdi
4011c9: e8 92 ff ff ff callq 401160 <lptoa>
4011ce: 48 8d 45 f0 lea -0x10(%rbp),%rax
4011d2: 48 89 c7 mov %rax,%rdi
4011d5: e8 6c ff ff ff callq 401146 <len>
4011da: 48 98 cltq
4011dc: 48 8b 4d f8 mov -0x8(%rbp),%rcx
4011e0: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx # check canary
4011e7: 00 00
4011e9: 74 05 je 4011f0 <longlen+0x58>
4011eb: e8 50 fe ff ff callq 401040 <__stack_chk_fail@plt>
4011f0: c9 leaveq
4011f1: c3 retq
From what I understand the canary works by alloating space on the stack immediately after the function that risks overflowing. A copy of the value at this address is stored elsewhere in a 'canary' register.
When the function finishes running, an xor operation is used, to compare the difference between the canary register and the value immediately after the stack pointer.
Conclusion
Processors are extremely limited in their scope, more of the magic we see on screen is intense maths done millions of times a second. Intel processors can only compare two values in an iteration and therefore must copy back the data to memory to reference later.
It is important to understand how your code translates to machine code at compile time. Interpreting the Assembly output of your code can help you gain intuition as to how your code actually runs. This opens up opportunities to optimizing your code to run faster. You especially should use bitwise operations liberally and understand how they work as they can make operations much more efficient.
Because a processor can only do one operation at a time it will try to pipeline many tasks into that existing clock cycle. In practice, this can be loading a value into the ALU in the same cycle that the previous result is sent back to a general purpose register for future use.